Curator won at AngelHack Brooklyn 2016 for best use of HPE Haven OnDemand’s API!
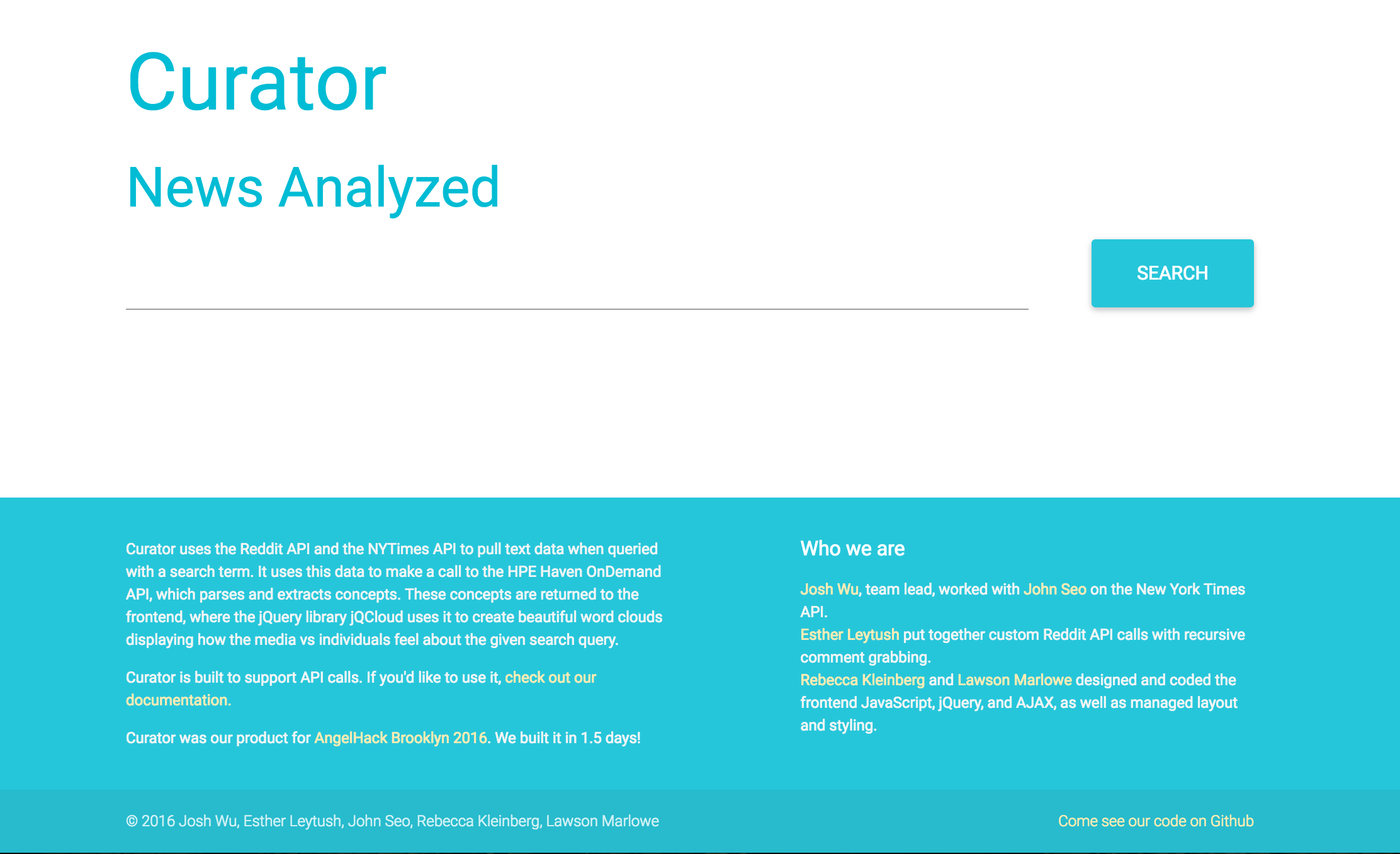
We built Curator as a Rails app. It uses the Reddit API and the NYTimes API to pull text data when queried with a search term, then makes a call to an HPE’s concept-extraction API that parses the text data. These concepts are returned to the frontend, where the jQuery library jQCloud uses it to create beautiful word clouds displaying how the media vs individuals feel about the given search query. Here’s some sample results when queried with ‘Clinton’:

Let’s take a look at how Curator works. Most of the work happens in our backend controller when a user triggers a search:
Let’s look at the call_to_Reddit more closely, one of our helper methods. It takes the search term and makes two searches with Reddit–one to /r/worldnews and one to /r/news–to come back with one post from each subreddit. We wanted to tackle both of the main news outlets on Reddit, and we needed to use Reddit’s search in order to limit our data to actual relevant posts that were more likely to have a high volume of comments.
For each of these two posts, we parsed them to get just their URLs, then triggered a call to parse_posts to grab their content.
This is where the meat of the work comes in. Using Reddit again, we used the two links we got from call_to_Reddit to get all the content for those posts. The data comes in as a giant hash, which we needed to parse for just its text elements. The post URLs and titles are preserved in one part of our hash, while the other part contains just the comment text data.
Getting the comments was tricky, in part because it was hard to understand which parts of the incoming JSON data were actually relevant, and in part because it required a recursive approach in order to preserve comments made on comments etc. Here’s what we ended up doing:
I later extracted the comment grabbing portion of the work that we did and turned that into a Ruby gem called reddit_comments.
Once we had our text data, it was time to make the call to HPE’s concept-extraction API. In order to do this, we decided to use the official havenondemand Ruby gem. This greatly simplified what we needed to do, making it possible to simply initialize a client and send a request. Here’s our code for that:
While getting the data from Reddit and NYTimes was costly in terms of how long it took, HPE had a very fast turnaround.
Started GET "/search?utf8=%E2%9C%93&term=Clinton" for ::1 at 2016-06-29 17:38:43 -0400
Processing by DashboardController#search as */*
Parameters: {"utf8"=>"✓", "term"=>"Clinton"}
Completed 200 OK in 5914ms (Views: 0.1ms | ActiveRecord: 0.0ms)
And that was it! After that we delivered the data in JSON format to our frontend and used the jQCloud library to create word clouds with the concepts that the HPE API extracted for us.
I’m Esther Leytush, and my team was Josh Wu, John Seo, Rebecca Kleinberg, and Lawson Marlowe. We’re all recent Dev Bootcamp graduates and we had a huge blast at AngelHack.